SSV.Network scaling roadmap
SSV Labs plans to reduce hardware requirements by up to 90% within a year through cryptographic, consensus, and networking optimizations.
Thank you Matheus, Moshe, Gal and Robert for co-writing
Every network has scaling limitations to consider, such as balancing security, hardware requirements, and performance. The SSV.Network is no different; we trade off different network properties to build the best product we can.
With ssv.network, it was decided (early on) to build a permissionless zero-coordination DVT network, allowing anyone to run an operator and register a validator. All without any form of off-chain coordination.

Zero-coordination prompted the team to use pubsub to interconnect all operators to the same network so discoverability becomes easy. This is done with a smart contract that coordinates all operators to their assigned cluster, giving way to resharing, EVM exits, and more.
Messages and propagation
Although there are a few bottlenecks, they all manifest in increased “consensus” time, i.e., how quickly a cluster comes to consensus and signs a duty. The faster a cluster can do that, the better its overall and individual validator performance is.
Duty lifecycle is shown below, going through multiple stages, each one requiring messages to be sent from operators to their cluster peers.

Messages are sent using the pubsub protocol, which is used by the beacon chain in a similar way. There are 128 topics to which validators are deterministically assigned; operators register to those topics to listen and broadcast messages to their cluster peers.
Topics are used to reduce the overall message traffic a single node needs to process, compared to a single-topic P2P topology where every message is propagated by and to every node.

Pubsub is a great tool for easy discoverability and access between operators, but it requires some overhead for operational messages (relating to pubsub’s internal workings).
Each message an operator processes requires CPU cycles. The more messages there are (from more validators), the more CPU cycles are needed. As a result, and with current network conditions, the number of CPU cores increased from 4 to 8 per operator to keep performance high.

Identified Bottlenecks
In the past six months, we’ve learned a lot about how the network works, identifying various optimizations that can greatly reduce the individual load on operators. This will allow the team to increase the overall scale of the network without exceeding the 4-core per operator entry threshold.
Areas of optimization:
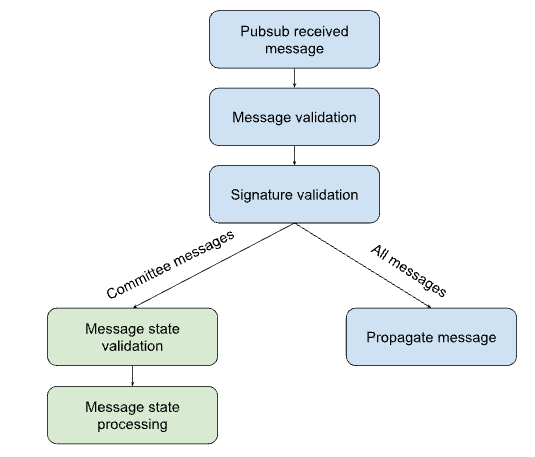
Below is the pipeline each message goes through, from being received by the node (over pubsub) to being processed (if a committee message).
The blue path is for all messages, regardless of who the sender/ receiver is.
The green path only applies if the receiver is part of the sender’s relevant cluster.
By monitoring node performance and CPU profiling of the protocol, it became obvious that the pipeline above can be classified into 2 distinct groups:
Group 1 is so significant that it actually takes close to 90% of CPU usage.
Originally, messages on ssv.network were signed using BLS12–381; it was chosen for 2 main reasons — Ethereum tech alignment & message aggregation.
Realistically, it became obvious that ssv nodes are broadcasting non-identical messages, making aggregation irrelevant. Another downside of BLS12–381 is how heavy it is to verify.

This means a new cryptographic scheme was needed to reduce the time it took to verify messages, since all messages a node operator receives need to be verified.
Why? Because of how pubsub works. Every node holds a score for every other node to prevent propagating malicious/ spam messages that can flood the network. Individual node scores depend on the “quality” of the messages it sends. In both ssv and the beacon chain, one of the parameters of “quality” is the validity of the message. Its signature is a crucial part of that.
After some benchmarking, moving to RSA signatures seemed to be obvious for a few reasons:
Due to the above findings, SIP-45 was born, merged, and already deployed on mainnet as you read these lines. A further improvement was to change RSA libraries, which are 10X faster than the standard golang crypto/rsa package. Overall, the move to RSA signatures reduced message signature verification time by 98%.
A further improvement in cryptography is to change RSA to a more succinct signature scheme, which is still much faster than BLS12–381. Using EDSA + ECIES was considered.
Each validator added to the network triggers a dedicated duty runner instance for each duty/ epoch.
A duty runner is a piece of code responsible for executing the duty fully; different duty runner types execute different duties, depending on the difference between them.
A duty life cycle is a 3 step process (the first step is not applicable for all duties).
During the post-consensus phase, operators collect partial signatures from all other operators, reconstruct a valid validator signature, and broadcast the duty to the beacon chain.
Below is a table detailing the number of messages each duty produces, ’n’ represents the size of a cluster (e.g., 4,7,10,13, …).


Having each validator start a consensus instance is wasteful. Some duties (attestations and sync committees) simply decide on , which changes every slot. This means that 2 validators that attest in the same slot can use the same decided beacon state.
In other words, if a cluster of operators has more than 1 attestation/ sync-committee duty in the same slot, it can get away with doing only 1 consensus instance for all of them.
In the best-case scenario, a cluster with 500 validators (the max per operator currently) will have an average of 15.6 validators attesting to each slot.
If operators reach consensus once per slot, followed by post-consensus, they can use 93.6% LESS messages (effectively 32*(n+3*n²) instead of 500*(n+3*n²)).
This optimization is called committee-based consensus and has been actively worked on by the SSV Labs team, hopefully, to be released to mainnet in Q3 of 2024. This change will require a fork!
From simulations performed on the current mainnet environment, we expect the total number of messages exchanged in the network to reduce to 13% of the current value. While the size of some messages may increase, after the for, we will see a ~50% reduction in bits exchanged in the network. This represents both lower processing overheads and lower bandwidth consumption for operators.


Another optimization, though less impactful, is to merge the post consensus step to be part of the commit message operators send.
This can reduce the message count (for the previous cluster example) to 32*n*(1+2*n)
While we strive to reduce the number of messages each new validator adds, the matter remains of how many operators need to process each message.
Imagine each operator needs to process all messages on the network. At the time of writing, each operator can have up to 500 validator shares assigned (out of 21K validators, May 19th, 2024). Suppose the operator needs to process all messages, even with the most optimized message scheme (per validator), the operator will spend ~97% of its time processing messages just to propagate them to other nodes so they can act upon them. Basically, 97% of the time, the operator is just a channel by which messages propagate.
With pubsub we can drastically reduce that number. SSV currently has 128 topics which divide messages by some deterministic function. An operator with a single validator will receive 1/128 of the overall network messages. An operator assigned to 500 validator shares will likely be registered to most, if not all, of the 128 topics, taking us back to square one.
We can see the importance of having an optimized validator-to-topic mapping function. A wasteful function will make operators process a lot of non-committee messages, whereas a good one will minimize them. The radio chart below shows the bias the current topic mapping function has towards robustness(Tr), which creates high topic weight(Tw) but low overall topics (|T|) and connected peers (|P|).
Tw is a measure of how “heavy” listening to this topic will be for a node.

Network topology is well under research by the SSV Labs team; several solutions were suggested with the required properties below:
Future network topology should reduce the weight(Tw) each topic has on the operator while not decreasing (significantly) topic robustness (Tr) and not increasing (significantly) the number of topics (|T|) and peer count (|P|)

One such solution is to map validators by their cluster, resulting in all validators of a specific cluster belonging to the same topic while still keeping the same upper-bound topic count. We can even consider some “topic heaviness” factor when dynamically calculating topic assignments so that topics have the same number of validators in them (more or less).
This new network topology is described in this SIP

This change to network topology could reduce message processing by ~98%, as operators will be required to process much fewer non-committee messages.
This number was achieved from a Monte Carlo simulation using the current mainnet dataset. In the simulations, we applied both network topology approaches, executed ethereum duties for 100 epochs and compared the number of messages an operator would process. At last, to get a broader view of the future, we tested how our model would perform for larger datasets and noticed that the performance gain can be sustained, as can be seen in the following image.

DVT is a new technology that is being widely adopted, prompting the need to optimize different parts of the protocol.
In the next 12 months, we will likely see ssv.network crossing 50K validators; the above solution will enable the community to support that while not increasing the barrier to entry of very expensive hardware.


